Improving the encoding of tweets. Stop words and lemmatizing.
Earlier, I ran into the problem where weights were assigned to some words, that as a human, make no sense. What stood out was the weights on commas and the word “not".
In this post, I describe the reasoning and tools I use to better choose the contents of the word_features. The goal was to make the explanations more credible and keep an accuracy rate of >80%. In the end, I failed to train a more human interpretable model at least on my laptop.
First I wanted a picture of how many weights were significant and how many weights were trivial.
I did this by counting the number of words above a certain arbitrary weight cutoff.
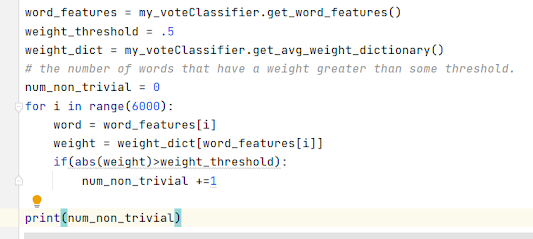
This returns 1090. Or about 18% of the dataset
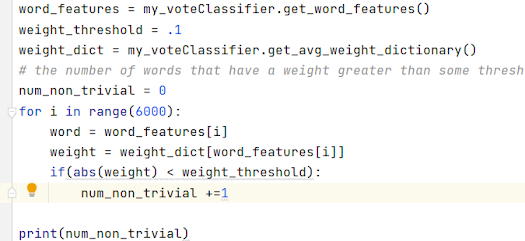
This returned 3029 elements. Or about 50% of the dataset. The presence or non-presence of about half of the data had a very small impact on classification. This would mean I could remove these elements from word_features without a substantial loss of accuracy.

A sample of the words with negligible impact on sentiment. This matches intuitive sense.

Here are some of the words with weights >.5. The weights assigned to these words make intuitive sense.
For code cleanness, I decided to create a CustomLemmatizer class to store all the methods related to stopwords and lemmatizing. I choose to do it like this because it would let me encapsulate away the lemmatizing to its own module since the only point of interaction was to determine_lemmas() on a string. Once I had debugged and was satisfied with the lemmatizing module I could safely forget the details of the implementation and focus on other parts of the code.
I choose to use the WordNetLemmatizer. This is a built-in lemmatizer that comes packaged with NLTK.
At this point I tried to make it work on a Naive Bayes algorithm but I kept on getting memory errors. It seemed like converting every document into a dictionary was taking up too much space.
After fiddling around with the implementations for a bit to try and reduce the size of the representation of the data I keep on getting an error that said I ran out of memory. It would take my laptop running at fullbore for about 2 hours to get that error. This was leading to very slow debugging processes.
So I decided to step back and try and implement the training on a distributed computing system. I wrote the script to limit the word_features to a much more manageable number but I could not successfully train the classifier I was aiming to anymore on my laptop. I could have just used the word_features with the Stochastic Gradient Descent classifier from earlier but I was trying to make the algorithm more intuitive to a human and SGD is an opaque model.
The next step then is to figure out how to train Naive Bayes on the cloud. I am currently take a Big Data Analytics Class at Eastern Washington University as part of the curriculum we are learning how to use Google Colab. I expect to learn how to use that tool and then to come back to this problem and train the classifier on the cloud.



