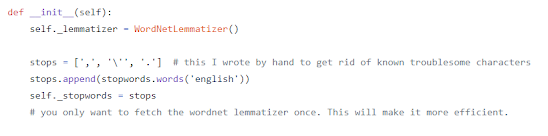
What is the relationship between own-price elasticity and the characteristics of an Ethereum mining firm?
I just enrolled in my Economics Capstone class at Eastern Washington University. It being my last quarter before graduation, this class ought to be the summation of what I learned. The purpose of the class is to write an empirical Economics paper for an academic journal. I figure while I am doing that, I can write up about the process of gathering and doing analysis on that data for this blog.
In this post I am going to talk about the amount of data that is free in this space and the problem that I am going to investigate in my capstone class.
For context, a few months ago my brother and I built an Ethereum Mining computer. As part of doing the research into the business feasibility of that project there were a few things that piqued my interest.
There are some technical terms to understand, to get the context of the problem I am investigating.
Blockchain: a decentralized, distributed ledger. The entire Blockchain is public and exists on every Ethereum node.
Ethereum: a cryptocurrency denoted as ETH
Wallet : The address on blockchain where the Ethereum is owned. A 40 Character Long string of case sensitive letters and numbers
4368d11f47764B3912127B70e8647Dd031955A7C is a wallet address
Hash: The base unit of computational work for maintaining the blockchain.
Mining: Computational work to maintain the block chain. You can think of this like having computers getting paid in ETH to solve hard math problems. This is measured in Mega Hashes /Second (Mh/s)
Mining Firm: An entity (can be one person in their basement or a multimillion dollar corporation)
Mining Pool: A platform that allows mining firms to pool their hashing power to reduce the variance in income.
If you want a better understanding read this.
The Blockchain is public. This means that anyone can see the details of any transaction. For this project, what interests me is the amount of ether, the date, the from address, and the to address.
The majority of all Ethereum mining takes place in mining pools and the wallets of those mining pools are publicly available. Those pools periodically send ETH to different mining accounts. Ethermine, one of the larger Ethereum mining pools, is responsible for about 20% of global Ethereum Mining. So if I can model that, then I can get a good grasp on 20% of the entire global market.
For example, I went to Ethermine.org, and scrolled down and clicked on a miner at random.

Here is the miner I clicked on. I have no idea who this person is. I just know that they are currently a miner at ethermine.org.
There is a bunch of information here so let's just look at the “Payouts” tab.
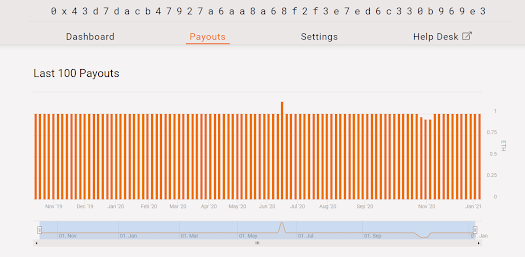
This shows that the dates that they have been paid that amount of Ethereum.
It is also possible to see their wallet in more detail using a Block Explorer. Check it out for yourself here.
You can then use a platform like Etherscan.io and see that the first transaction on their wallet was on July 20, 2018. This lets you infer when they started mining Ethereum.
It is absolutely shocking that this kind of data is free. There is a massive amount of free raw data so this seems like a doable exciting project.
To get a grasp of how utterly ridiculous it is that this kind of information is publicly available let's look at what this kind of data would look like in another context.
Imagine that Amanda is a budding entrepreneur looking at opening her own hair salon. In this hypothetical world, all haircuts are identical and the market price of a haircut varies widely. She can look up and get detailed analytics, for free, the number of haircuts done by every single other hair salon since the invention of hair. She can see that when the price of haircuts is high, firms start producing more haircuts and when the price is low, they start producing less haircuts. This is easy to understand at a theoretical level but the important thing is the speed with which they ramp up or ramp down production. If she can be substantially faster than her competition she would be in a good position to be very profitable.
That information is essential to knowing if it would be prudent to even go into the hair salon business. It also informs the decision of whether or not to ramp up production, and if so, by how much.
There is more complexity in the Ethereum miners model than in the simplified example above. I plan on explaining more of that complexity in a later post.
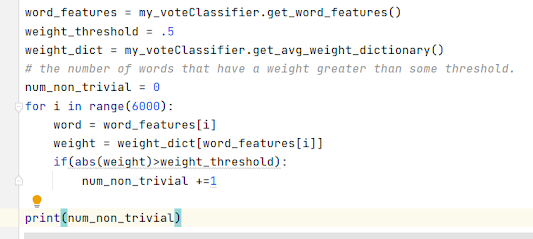
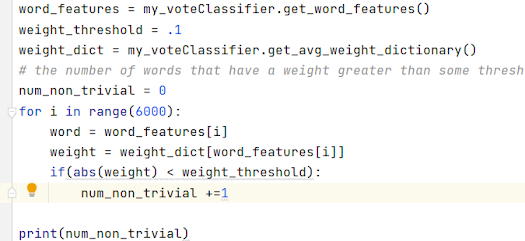
So the problem I will be investigating is what is the own-price elasticity of different categories of Ethereum mining firms. Are the large firms faster and more responsive to price changes, or are the small firms faster?