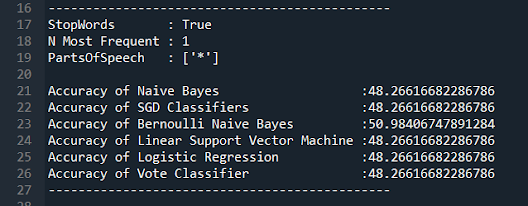
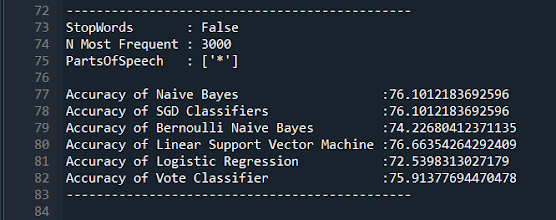
I had just looked at the relationship between Parts of Speech and Accuracy and next I wanted to train a classifier to be used specifically on tweets.
This post is a write up about my decisions and the process I used to train a classifier on the labeled tweet data. I used this dataset from kaggle of tweets labeled by sentiment as my source.
The first part of building a model is to explore the data.

Screenshot of a section of the raw data from kaggle.
This contained more information than I needed so first I needed to clean it up into a new file.
I only care about the body of the tweet and the Positive or Negative sentiment so my first step was to write a script to simplify the data into a file with only the tweet text and the sentiment. You can see the method I wrote to simplify the data here.
After I ran that script the data looked like this.

First, I tried using a Linear Support Vector Machine since I already knew how to use it but after running it let it run for a few hours I got this error.

Inside of this LinearSVC it had converted a vector of Booleans into a vector of floats. That unfortunately would take much more memory then I had access to on my laptop. This led me to try and find a classifier where I could train it in batches rather than all in a single go.
I ended up setting on using the Stochastic Gradient Descent Classifier from the sklearn module.
I choose this because it is a common algorithm for text classification and it has a built in partial_fit() method. This would let me train in batches so I did not have to load the entire training_data into my RAM.
The first step was to convert a string of text into a very long boolean vector. This along with the target was then passed into the partial fit method as a pair.

The code I wrote to convert a string, classification pair into a long boolean input vector and boolean classification.
After writing this I let it run, it took about an hour to make a boolean vector of length 5000 for each tweet and about two hours to make a boolean vector of length 10000.
Interestingly, since I was training the classifier in batches, after each training session I could compute the accuracy on a subset of the yet unseen data. I wrote a script to write out 10 accuracy scores to a file after each training session. I did this for using 5000 words as features and 10000 words as features. That is shown in the graph below.

It looks like the vast majority of the learning happens early on and plateaus after 400k tweets. This logarithmic learning curve is consistent with what I have seen elsewhere and the other tests I did earlier in this series.
After I created this data I uploaded it to a local SQL server on my laptop to run some basic queries.
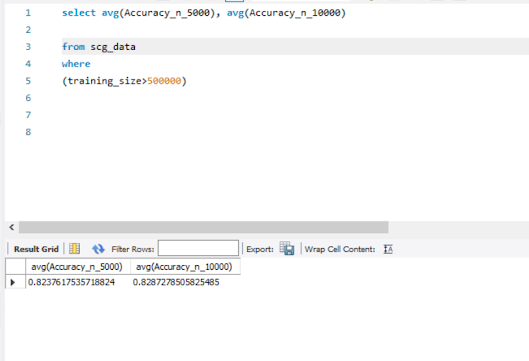
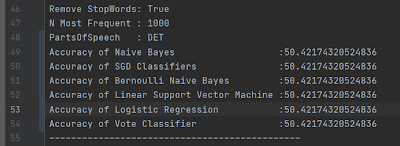
I wanted to compare the accuracy when the training size is larger.

After training the classifier on a million tweets it got up to about 82% accurate.



On average, after training on almost all of the data this Classifier was about 82% accurate. This is about as good as you can expect with sentiment analysis since the best algorithms are only 80-85% accurate.
Because, there is not very much benefit in those last 5 thousand features. When I roll it out for use on live tweets I might choose to use a smaller features size.
Later on, I might want to manually limit word_features to remove words that were not communicating meaning.
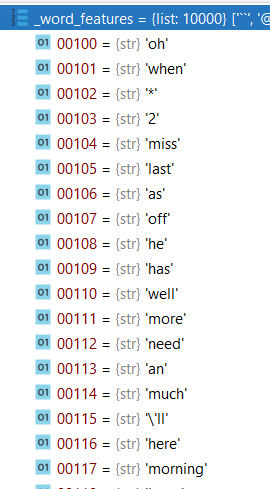
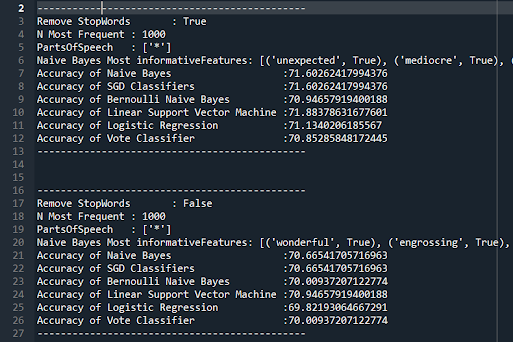
This is an excerpt of the word_features used in the Num_features=10,000. Many of these words clearly do not communicate sentiment to a human but were still treated as features in the classifiers. I doubt looking at the word ‘as’ can tell anything about sentiment so it would improve the classifier to ignore that word. For this post I did not remove any words from word_features. Later on it might make more sense to build a custom list of stopwords for twitter.
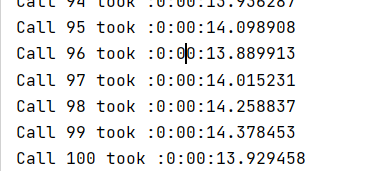
Time it took to for each partial_fit() when Num_features is 10000 and the training size is 10,0000
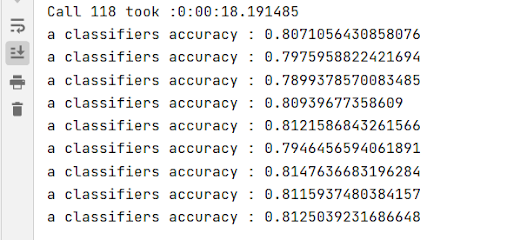
The accuracy rates of training on the 95% of the data using Num_features =10,000. These are respectable accuracy scores.
Next, I did some spot checks to make sure that sentences that were obviously negative would be classified as negative and vice-versa.

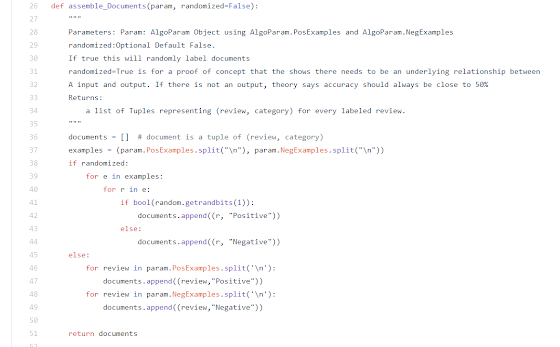
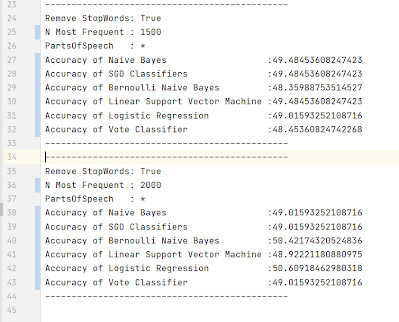
This is clearly not a positive sentiment. So something must be wrong. I did a bunch more tests and I kept getting positive on every sentence I tried.
So to see if this was just anecdotal and I was just getting unlucky I wrote a script to query twitter and scrape tweets written in the English containing the word “hate”. If my algo was worth its salt, most of these tweets would be labeled as negative.


I let this run for about 3,000 tweets. Much to my chagrin every single tweet was labeled as positive.
So now I had a large amount of debugging to do. First, I wanted to see that the process to convert it to a vector was working properly. To this end I wrote un_vectorize method. This would take a vector and spit out a ‘bag of words’.
I ended up saving the word_features in the vote_classifiers along with the accuracy scores within the VoteClassifier object.


Eventually I figured out the problem was when I wrote:
if (classification).
Return ‘Positive’
Else:
Return ‘Negative’
The variable classification was a string when it got to this section of code. In Python, if(string) will always return true. So after about 4 hours of debugging I fixed it by rewriting a single line.

I did some spot checks on sentences I wrote and it all looked fine.
A vector that contains only False values would contain only words that my method has never seen before. In that case there is no good way to classify it so I wrote a clause to return ‘Unsure no known features’ to not get a meaningless classification.

Next, I ran some tests on tweets containing “hate” and “love” almost all of the tweets with the word “hate” were negative and almost all of those that contained “love” were positive. This means that the classifier passed the smell test on live raw tweets.
Looking at a live feed of tweets with the word “love” I got this gem:
“I learned this morning that my parents unconditional love expires on New Years Eve” was mislabeled as ‘Positive’ sentiment.
After finishing the debugging and training of the SCGClassifers, I now had several different VoteClassifiers pickled on my laptop that were, at least at first glance, ready to be used on real world twitter data.