To get a better understanding of why the classifier makes a classification first there needs to be a more in depth understanding of the data encoding process. Because actually determining the sample space is not trivial I just estimated what I think are some reasonable upper bounds.
A tweet begins as a member of the set of all possible tweets. Without going into much detail about sample spaces, it is safe to assume that the set is very large. That set contains information about word order and if any words are duplicates. The next step in encoding is to convert that tweet into a list of unique words. When that conversion takes place, information about the order of words and if there are any duplicates is lost. In theory this means that multiple tweets will be mapped onto a single list of unique words. In practice, this is unlikely to be significant since the sample space at this point is still uncountably massive. In addition, even if more than one tweet is mapped onto the same list of unique words those tweets would likely have the same sentiment to human readers.
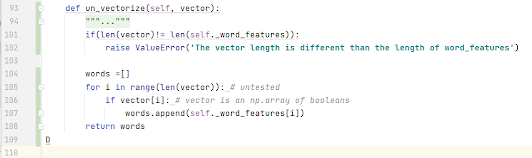
Once it has a list of unique words the find_features() method will walk through to create a boolean vector where each entry in the vector is a boolean of the words that is present in the tweet.
Here I think a simplified example would make it more clear.
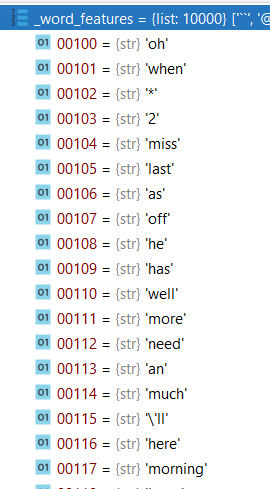
Let word_features:
[‘great’, ‘today’, ‘sad’, ‘happy’, ‘I’, ‘exciting’]
Let the list of unique words be:
[‘sad’, ‘I’, ‘today’,‘headache’,’woke’, ‘up,]
This would convert into a boolean vector:
[False, True, True, False,True, False]
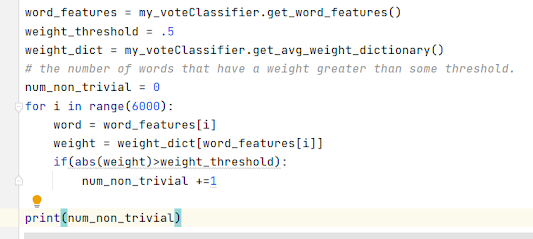
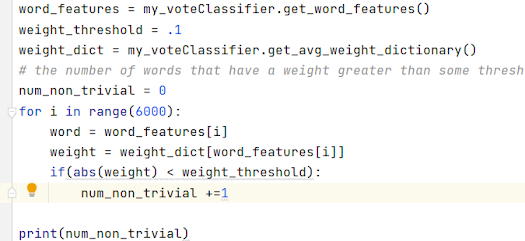
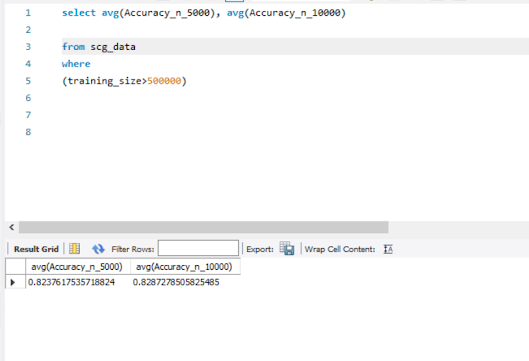
This is a simplified example where word_features only has 6 elements. This corresponds to a sample size of 2^6 or 64. What that would mean is that every possible tweet would be encoded into only 64 unique boolean vectors. Clearly this is much too small to capture the real differences between tweets. In the model I trained on there are 6000 elements in word_features. This would mean that the total sample space would be 2^6000 or a number with 1807 digits. This set is still very massive. Even still, whenever a word occurs that is an element of the 6000 word_features that information is lost.
Interestingly, the set of all possible tweets is so large that even after you remove all information about word order and duplicates, then remove all but the presence or absence of 6000 words, the sample space is still massive.
I expect that in nearly all cases there will not be more than 50 words that are present in both the list of unique words and the word_features. So the sample space can be thought of as being about (given 6000 options choose <=50) or about 2^400.
But in practice it is good enough to know that the sample space is so large that it is very unlikely that multiple tweets with different sentiment will be mapped onto the same vector.
So while the sample space of tweets is still massive, a large amount of information is lost in the encoding process. Since the algorithm is only trained on the encoded information, it can only explain based on that information. This means it can only explain its predictions based on the presence of a small subset of words in the original tweet.
The knowledge that a classifier only looked a few words is not very informative to a human reader so I choose to reach into the internals of the SGDClassifier look at the weights assigned to each word in word_features.

This comes from the attribute in SGDClassifier.coef_. These numbers correspond to weights assigned to each of the dimensions within the sample vector. In binary classification you can interpret these weights as the positive or negative significance of each term.
An easy way to interpret the weights is to think: Large positive weight : strong predictor of positive sentiment. Large negative weight : strong predictor of negative sentiment. Small absolute value of weight : not a strong predictor.
Once I had this information I could write some methods to demystify the classification process. I decided to write these methods inside of my VoteClassifier class.
First, I wrote a method to pair each word with the average weight assigned to it by the classifiers.

Next, I wrote a method that simulates the encoding process to simulate the information lost. This would return a list of words that were the basis for the classification.


I then wrote a method to calculate the weights assigned to each word. This a human would be able to interpret as seeing the list of words that had the most impact on the classification. 

A human can look at the weights and see that the word “sad” was many times more clearly negative than the word ‘so’. The -4.2 weight of “sad” is much larger than -.19 weight of “was”.
The weights assigned to these words make intuitive sense to a human reader. That is a good sign. Later on there are some
Next I wanted to see the average score given to a tweet. Since the classifiers work internally with a floating point number and only return a boolean I could reach in and look at how close to 0 or 1 that float was. Because I encoded Negative Sentiment as 0 and Positive Sentiment as 1 you can interpret the scores with a large absolute value as meaning high confidence in the classification and scores with a small absolute value as meaning a lower confidence in the classification. Scores that are near 0 and 1 are particularly ambiguous.

Finally, I stitched all of the methods together in an explain_choice() method. It would explain in plain english what features had the most significance. To do that I needed to sort by the absolute value of the feature weights.

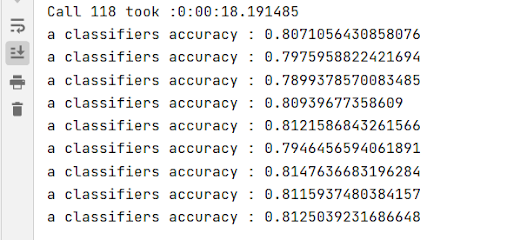
Here are some sample runs of the VoteClassifier.explain_choice() method.








After looking at the preliminary results of the explain_choice method I think that the next major way to improve the classification algorithm is to create a list of words to be excluded from word_features.
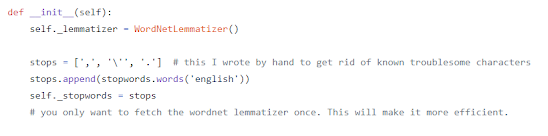
Earlier in this series I tested limiting by parts of speech and stopwords. Removing stop words did not seem to have any impact on accuracy but just reduced the total time it took to train the classifiers. Since I was not doing any training that would take longer than a few hours it did not seem worthwhile to add to make more code more complex to save a little time on the training.
Looking at it now, it seems like the benefit to a list of stop words is not in the impact on accuracy but in the removal of spurious relationships. This, if done well, would not have an impact on accuracy but it certainly would make the explanations for humans more intuitive.
It might make sense to also lemmatize the words before converting them to vectors. Lemmatizing is a process that converted the words “cry”, “cried”, and “crying” into a single word before encoding. This would mean that word associations are not limited by word tense.
It makes no sense to a human that a comma should have a weight of +.49.
The word “not” has a weight of -.81 and I am not sure what to make of that. On one hand, based on the weight, the presence “not” is a predictor that a sentiment is negative based purely on the frequency it is in positive or negative examples. On the other hand, “not” only makes sense when it refers to something, “not good” and “not bad” have opposite sentiment. This makes it unclear if it is best to keep “not” in the word_features. It will likely make the classifier more accurate to keep it in, but will make its explanations less credible to a human.