After removing stop words in the last post, I was curious about what parts of speech impacted accuracy the most. For example, if only verbs were treated as features, would the accuracy be better or worse than if my model considered every word? I tested several different parts of speech, and when there were enough unique features, I took some screenshots of the results below.
The first section is what decisions I made in training the classifiers. The second section is some theoretical considerations about the limits of this type of model.
There are a couple of ways of parsing by parts of speech. I choose to use the nltk.pos_tag universal tagset since it makes the code more readable and was specific enough for my aims.
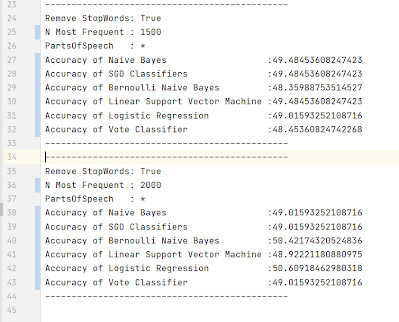
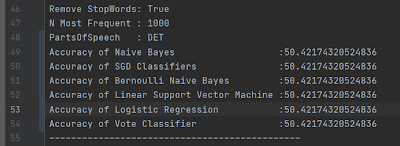
I choose to test nouns, verbs, adverbs, adjectives, determiners, auxiliaries, and punctuation. I then compared the results to by not limiting by part of speech. For each model, I set a num_features=1000 since it would make the training faster and would give a reasonable accuracy rate.
Loop to generate a list of AlgoParams to compare accuracy.
The way that these algorithms determine something as fuzzy as sentiment from text is to first convert the text into a list of features. This kind of a self-referential definition but the way that I think of features is as words that convey meaning about sentiment.
This is clearest to understand when looking at the Naive Bayes. In that algorithm each word is treated as a feature where and the weight of each feature corresponds to the frequency that it occurs in examples in the training data that are labeled as positive or negative. This would mean that words that occur many times in examples labeled negative would have a high negative weight assigned to them. If that word occurred then in an unseen example, that would make it more likely to think it is negative.
I used the 'bag of words' approach for simplicity. This version ignores different ordering of words. It reduced every possible sentence into a 1000 series of booleans representing if a feature is present in a review. In practice this means that each sentence is converted into a 1000 long vector of almost all False with a few True entries.
My assemble_word_features() method treats the 1000 most frequent words in all_words as features. All of the reviews were then converted into features sets based on the most frequent words.
When I tried to only treat punctuation (“PUNCT”) as features, there were not 1000 unique words that were labeled as punctuation. Since I have already established that there is a logarithmic relationship between the size of word_features and accuracy, I decided there were not enough unique words to be treated as features the accuracy would be low. Therefore when there were not 1000 unique words I did not train a classifier for that part of speech.
The way to interpret these results is to compare the accuracy of the different parts of speech. I expected that the accuracy of not limiting by part of speech to be more accurate than any single part of speech. The simple explanation is that if you feed less total data into the classifiers then they would tend to be less accurate, at least within the testing data.
Because of how the binary classification algorithms are set up, each classifier must be between 50%-100% accurate. This makes intuitive sense because if a classifier was 20% accurate, you could just swap the labels causing it to become 80% accurate.
The final accuracy score is a both a function of how good the classifiers are at finding the relationship between the chosen features and sentiment and how much of a relationship there actually is between chosen features and sentiment. There is an upper bound less than 100% accurate since in natural language the sentiment is not always positive or negative but sometimes ambiguous.
Two humans can look at the sentence:
“I liked the acting but did not like the cinematography”
In good faith, they can disagree if the sentiment is positive or negative. If we were to get the author of that review and ask them “Did you have positive or negative sentiment when you wrote that review?” First they would look at you strangely since that is quite an odd question and second, it's not even clear that there is a correct answer they could give. Because some reviews are ambiguous, no algorithm could be 100% accurate.
Accuracy is also limited by the actual relationship between features and sentiment. If there is no relationship,(e.g. sentiment is completely random) accuracy should always be a coinflip. I tested this by randomly labeling reviews to be positive or negative and looking at the accuracy of the classifier.
Code to randomly label documents
You can also see the accuracy here is always close to 50%. I would expect that if I were to run this a large number of times it would form a normal distribution around 50%. See the test results here.
There are also context-specific biases that need to be considered. For example, if in my training data there are several glowing reviews for a Marvel movie then the classifiers could learn to associate “Marvel” with positive sentiment when that relationship might not exist in the broader world. If I then were to use these classifiers to look at the sentiment of tweets about a later Marvel movie that happened to be a flop, the model would show an artificially high rate of positive sentiment.
In that case it would be better to limit the word_features that convey sentiment in the most universal context rather than trying to apply context specific sentiment about movie reviews. This would mean only looking at adjectives or only looking at adverbs.
There are a variety of features that I would expect to have no or nearly no predictive power. I include them to verify that my intuition matches the output. For example, I didn't expect determiners (words like “an”, “this” and “those”) to communicate anything about sentiment. So if I were to treat only determiners as features I would expect the accuracy would be close to 50%.
Determiners do not have any sentiment prediction power. This is consistent with what I expected.
Nouns are better at determining sentiment than other parts of speech. This was surprising since I typically think of nouns as value neutral. Eg “movie” does not convey sentiment but “good movie” and “bad movie” does.
It surprised me that adjectives are less predictive than nouns.
Accuracy of not limiting by part of speech. This is the standard that the accuracy of other parts of speech is compared to.
In conclusion, the accuracy of limiting by parts of speech is strictly worse than not limiting by parts of speech. This was the case for my training and testing data but it is unclear if it would be better or worse for looking at Twitter sentiment. There are reasons to think it would be better to limit by only adjectives when looking at Twitter even though it has a lower accuracy rate on the training data. Without a prelabeled set of (tweet:sentiment) pairs to compare the different classifiers on accuracy it is difficult to answer the question statistically.
Fortunately, I found a dataset on Kaggle that would be much better to use as a training set for looking at sentiment on Twitter. I will be writing up that process and my decisions in training a classifier on that data in the next post.
Tuesday, December 22, 2020
What is the relationship between Part of Speech and Accuracy?






Data Viz and Analysis of the Numerai Leaderboard
There is a protocol built on Ethereum called Numerai. They explain it in more detail on their website but in essence it is a way for anyone...

-
When I was working through this project, there were a few questions that I wanted to investigate further. I used the labeled short reviews t...
-
 There is a protocol built on Ethereum called Numerai. They explain it in more detail on their website but in essence it is a way for anyone...
There is a protocol built on Ethereum called Numerai. They explain it in more detail on their website but in essence it is a way for anyone... -
I had just looked at the relationship between Parts of Speech and Accuracy and next I wanted to train a classifier to be used specifically ...

