When I was working through this project, there were a few questions that I wanted to investigate further. I used the labeled short reviews that were provided in this lecture series. See the labeled dataset here.
What is the impact of removing “stop words” on accuracy?
What is the impact of the number of words as features on accuracy?
Before answering these questions I needed to write some new code.
I created a data class called AlgoParams that held the positive and negative examples, a Boolean to remove stop words or not, how many words to treat as features, and what parts of speech to consider. I don’t filter by parts of speech in this post but I do later on. This made it easier to tease out the relationship between the different parameters and accuracy.
I refactored the dataLabeling.py module to work with AlgoParam objects. I should have noticed this when I refactored it, but I had hard-coded the number of features at 3000. This caused me a headache since the first few test results were not actually testing any differences. I eventually noticed this and to see if there were any other things I was missing I tested some AlgoParam objects that were intended to have terrible accuracy.
Lastly, I wrote a method to compare the accuracy of the different algorithms. I called this writeAlgoEvaluation(param, classifiers, FeatureSets). It wrote out details of an AlgoParam and the accuracy of the different types of classifiers. For some of the runs I made it write in a more human friendly way while in others I wrote more like a .csv file. Look at all of the test results here.
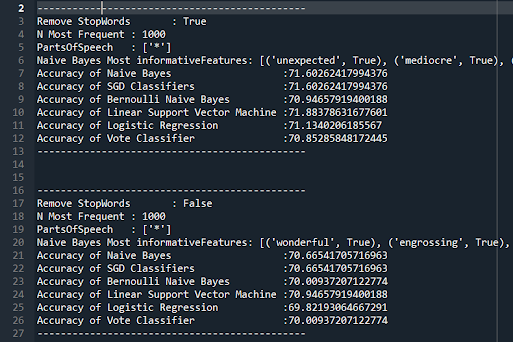
When I removed stop words, there was a negligible effect on accuracy. This is consistent with intuition and theory.
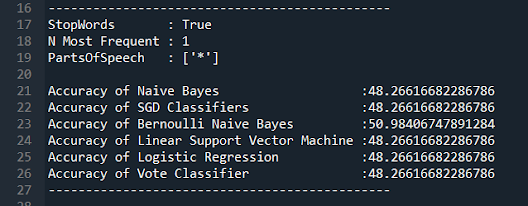
When N=1, the accuracy is a coin flip. This is what I expected since knowing that a single word is present in a review is not enough to tell if that review is positive or negative. If I tell you that a movie review contains the word “movie” do you really know anything about the review?
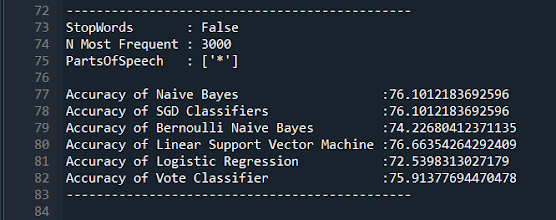
These were the parameters used by the lecturer and they were about 76% accurate. All things considered this is a respectable accuracy.
Next, I looked at the relationship between the number of words as features (N) and accuracy. I tested different values for N from 100 to 5000 in steps of 100 with a 90-10 and 80-20 Train/Test split. This took about 6 hours on my laptop and gave me 600 different accuracy scores.

Sample output of effect of number of words as features (N) on accuracy in a .csv format.
After it finished running I created a scatter plot in Google Sheets of the results. You can download the results here.

The accuracy plateaued at about 75%. Ironically, this was the same as the accuracy I would have gotten if I just used the same parameters as the lecturer.

I did not expect this, but the variance in accuracy tended to increase with N.
My explanation for why variance tends to increase with N because when N is larger, less frequent words are treated as features and those features contain more random noise.
Imagine if the word “refreshing” occurs 500 times in positive reviews, and 100 times negative reviews. Then imagine if the word “Spanish” occurs 5 times in positive reviews and 1 time in a negative review. If I tell you a review contains “refreshing” it is stronger evidence that the review is positive than If I tell you a review contains “Spanish.”
When N is small, it will capture more words like “refreshing” and when N is large it will capture more words like “Spanish”. It is reasonable to expect when wordFreq=600 the impact of randomness is less than when wordFreq=6. It makes sense that when N is larger it contains more relationships that are just random noise.
There was a small difference in the variance the 80-20 and 90-10 split.
The average variance of the 80-20 split was 2.01 had a standard deviation of 1.64. The average variance of the 90-10 split was 1.83 and had a standard deviation of 1.30. This is small and mostly disappears if you remove the outlier in the 90-10 split at N=2900. Overall, the difference is negligible as both follow the same general trend.
After a certain point, N~1500, there are only negligible gains in accuracy but there is a clear increase in variance. For most purposes, using N value of close to 1500 is about as good as you could expect given the classifiers and the dataset.



